Créer automatiquement son bilan carbone avec de l'IA.
Source d’inspiration : start with why
Ce retour d'expérience (REX) retrace les étapes qui nous ont permis de concevoir, en deux mois, un Minimum Viable Product (MVP) exploitant l'intelligence artificielle. Notre objectif : maximiser la valeur du conseil en durabilité en réduisant drastiquement le temps consacré aux tâches manuelles, répétitives et fastidieuses.
Why ? Privilégier le conseil plutôt que le traitement des données.
Avant de réduire ses impacts environnementaux, une entreprise doit comprendre d’où proviennent ses émissions de gaz à effet de serre. Cela passe par la mesure de son empreinte carbone, incluant ses propres activités et celles de ses fournisseurs.
Cette empreinte permet de trouver les “points chauds” (les postes les plus émetteurs) afin de prioriser les actions réduisant fortement les impacts environnementaux. Si on fait le parallèle avec la comptabilité classique, de la même manière qu’on analyse les postes de dépenses les plus élevés pour optimiser les coûts, on analyse les postes d’émissions les plus importants pour réduire l’empreinte carbone.
Un des enjeux pour produire cette empreinte réside dans la collecte et la classification des données. Une approche courante consiste à partir des données d’achats (factures, ERP, fichiers Excel) et à les croiser avec des bases de facteurs d’émission (comme ecoinvent) afin d’associer à chaque produit ou service un impact carbone.
Ce n’est ni plus ni moins qu’une comptabilité où on remplace le prix unitaire d’un produit acheté par son impact en gaz à effet de serre. On multiplie l’impact par la quantité de produit acheté et on somme le tout pour connaître l’empreinte globale de son entreprise.
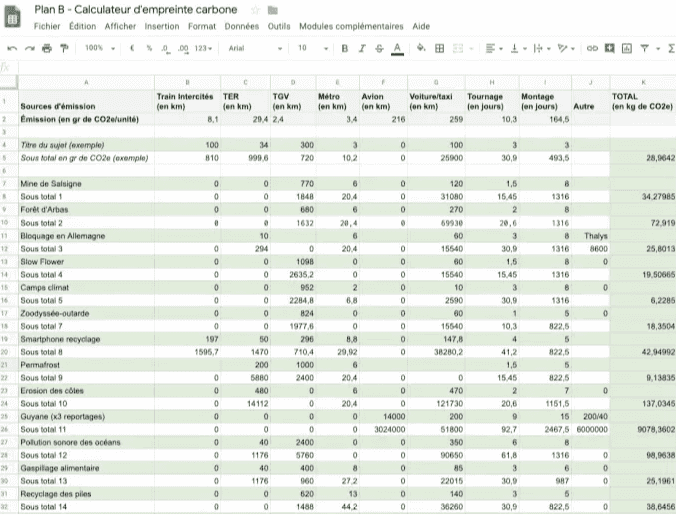
Source : ladn.eu, extrait du bilan carbone du journal Le Monde
De la même manière que les entreprises vont demander à un expert comptable de faire sa comptabilité, elles pourront faire appel à un expert durabilité pour sa comptabilité carbone. L'intervention d'un expert en durabilité est souvent cruciale pour garantir la bonne adéquation entre les données recueillies et les bases de facteurs d'émissions. C'est précisément ici que nous intervenons.
Notre partenaire, un expert du domaine, sollicite notre appui pour accélérer ce processus encore largement manuel et chronophage. C'est dans ce contexte que l'intelligence artificielle peut apporter une aide précieuse.
How ? L’IA à la rescousse.
Comment mettre en place un système capable de faire automatiquement le lien entre un produit et le facteur d’émission le plus pertinent ?
L'accès aux données est un défi de taille dans le développement d'une IA. Les informations précises sur la chaîne d'approvisionnement, étant confidentielles, compliquent l'entraînement des modèles sur des données propriétaires, rendant cette démarche onéreuse, techniquement ardue, voire illégale.
Heureusement, il existe des techniques permettant de se baser sur des modèles d'IA open source sans nécessiter de jeux de données internes massifs.
En utilisant les approches de zero-shot learning, de l’embedding et du calcul de distance entre deux phrases, nous avons pu mettre en place un système qui fait correspondre un nom de produit à un nom de facteur d'émission.
Zero-shot learning : définition
C’est l’idée d’utiliser un modèle généraliste (Ex: Chatgpt, Claude, Mistral, Apertus, …) déjà entraîné sur un domaine (ici un corpus de textes) pour résoudre un problème spécifique (ici faire correspondre deux textes décrivant un produit et une référence dans une base de données de facteurs d’émission). Les performances sont généralement suffisantes pour produire des résultats exploitables rapidement, sans phase lourde de collecte ou d’annotation de données.
L’embedding, pourquoi faire ?
Cette technique qui prédate les LLM permet de transposer des mots, des expressions ou maintenant des phrases vers une suite numérique, plus précisément des vecteurs.
Historiquement, des modèles comme Word2Vec ou GloVe étaient utilisés pour la traduction de mots en vecteurs, mais ils n'utilisaient pas la même architecture que les Large Language Models (LLM) actuels. Aujourd'hui, les meilleures méthodes d'embedding reposent sur des LLM basés sur l'architecture Transformer. Ces modèles (comme BERT ou GPT) génèrent des représentations vectorielles bien plus riches sémantiquement et contextuellement, marquant une nette amélioration par rapport aux approches précédentes.
Cette technique compare des textes non pas sur la similarité des mots, mais sur le sens qu'ils véhiculent. Par exemple, bien que les mots "adulte" et "enfant" soient différents, ils partagent la notion d'âge, un point commun sémantique.
Une illustration est fournie ci-dessous à titre d'exemple. Elle utilise des vecteurs dans un espace tridimensionnel (3D) pour illustrer que la distance entre deux vecteurs peut représenter la dimension de l'âge.
Il est important de noter que dans la pratique actuelle, les vecteurs possèdent généralement autour de 4096 dimensions (ce qui les rend difficilement représentables). De plus, la distance entre ces vecteurs ne porte pas un sens aussi simple à interpréter que dans l'exemple 3D (où l'analogie « chaton est à chat ce que enfant est à adulte » n'est d'ailleurs pas parfaitement adaptée).
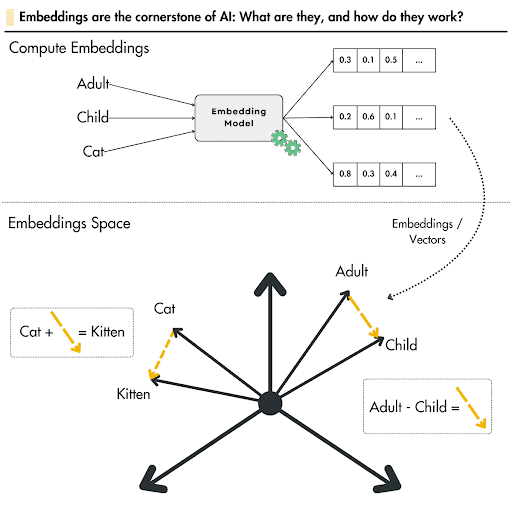
Source : lightly.ai
Dans notre cas, on utilisera cette technique de comparaison pour trouver dans un dictionnaire (la base de données d’impacts) lequel correspond le mieux aux produits se trouvant dans les tableaux comptables.
Exemple : l’entreprise K a acheté 5 tonnes de coton pour faire des T-shirt, le nom le plus proche dans la base de données ecoinvent (la plus connue dans le domaine) sera “market for fibre, cotton”.
“cotton” - “market for fibre, cotton” < “cotton” - “market for electricity, low voltage”
On cherchera donc pour chaque produit de notre inventaire, la phrase la plus similaire sémantiquement avec celle dans la base de données des émissions.
What ? Une première itération qui permet d’avoir des feedbacks rapides
Sur le papier, tout semble bien engagé, maintenant, il faut valider l’idée avec un modèle et des vraies données.
Nous validons rapidement l'approche par des tests de quelques jours avec des listes de produits issues de données publiques. Pour l'embedding (la transformation de mots en vecteur), nous sélectionnons des modèles d'IA open source de petite taille. Les LLM puissants (type ChatGPT), conçus pour la génération et le raisonnement, sont superflus pour cette simple transformation en vecteur. Utiliser de tels modèles serait coûteux et inutilement lourd (sur-ingénierie).
Pour se faire une idée du ou des meilleurs modèles, nous nous appuyons sur les leaderboards de huggingface, qui comparent les modèles selon différents benchmarks de similarité sémantique. Tous ces tests sont basés sur un principe simple, le calcul de “distance” entre deux vecteurs. C’est ce que nous allons chercher à faire nous aussi pour ce besoin.
Après quelques expérimentations, nous arrivons à la conclusion que nous avons un bon pourcentage de “vraies” correspondances par le modèle. Les experts restent meilleurs mais les résultats sont satisfaisants pour déployer une première version de notre PoC qui permettra de transformer le travail fastidieux de chercher toutes les correspondances en une validation avec un score donné par le modèle pour l’aide à la décision.
Pour favoriser une adoption rapide de nos outils et réduire le temps de développement, nous déployons une interface utilisateur très minimaliste. Dans un premier temps, les utilisateurs pourront obtenir des résultats rapidement en fournissant simplement un fichier Excel comme source de données. L'outil complètera alors une colonne avec la référence correspondante, extraite de notre base de données d'impacts.
En quelques jours le service est déployé et présenté aux équipes. Les premiers retours des utilisateurs ne se font pas attendre. La demande la plus forte est de prendre en compte la localisation du produit. C’est un critère primordial pour le calcul d’impacts.
Avant d’améliorer le modèle, avant d’améliorer l’UX, nous nous sommes attelés à implémenter cette demande. Deux semaines après, le MVP était là, c'était Viable pour les utilisateurs.
Next ?
Après les premiers retours d’usage du MVP, les prochaines itérations tendent à tirer parti du savoir-faire des experts pour pouvoir influencer le modèle dans ses choix, augmentant ainsi ses performances.
Trois exemples d'itération possibles:
- Le premier en termes d’expérience utilisateur, aider l’expert à se focaliser et travailler plus en détail sur le ou les hotspots (Example: L'énergie utilisée pour les transports de marchandises) grâce un rapport interactif montrant les plus gros secteurs d’impacts avec des degrés de confiance pour une aide rapide à la décision.
- En améliorant le modèle pour mieux caractériser les flux (Exemple: donner une indication au modèle qu’il doit plutôt trouver des facteurs d'émissions d'énergie renouvelable pour un secteur d’activité donné afin d'être plus précis dans le bilan carbone...)
- Entraîner des modèles spécifiques par domaines métiers (Exemple: les camions de transport de béton n’ont pas les mêmes caractéristiques que le camion frigorifique pour le transport de fruits et légumes).
En conclusion, en proposant un premier incrément améliorant la productivité et en prenant en compte les retours métiers, nous avons pu en 2 mois aider des dizaines d’experts à consacrer plus de temps au conseil auprès de leurs clients pour des actions à impact fort plutôt qu'à passer du temps à chercher le meilleur facteur d'émissions pour produire le bilan carbone de leurs clients.
Nous reconnaissons l’importance de bien cadrer un projet, mais nous sommes avant tout obsédés par le feedback rapide des utilisateurs, meilleur moyen pour répondre aux besoins clients.