The Cloud is really expensive! (part. 2)
A Cloud migration cannot be improvised. In the first part, we saw that it requires a re-evaluation of the company's technical assets. This second part focuses on the organizational transformations necessary to fully benefit from the advantages of the Cloud.
The Cloud has the advantage of making resources available on demand with a pay-as-you-go pricing model. The promise is to pay only for the individual services you need. It is no longer necessary to over-provision. The disadvantage of this model is cost variability. Without monitoring, bills can quickly skyrocket. It is from this observation that the FinOps approach was born, with the objective of combining technical performance and financial discipline.
In our experience, every company migrating to the Cloud faces a hefty bill at least once. Examples range from a misconfiguration that went unnoticed to a function called by an infinite loop. To guard against this risk, two fundamental principles must be adopted. Omitting them means taking the risk of seeing your Cloud migration turn into a nightmare.
The first principle is to monitor deployed resources. To be aware of any anomaly, it is necessary to implement observability and alerts for both infrastructure and applications.
The second principle is product team autonomy. In the Cloud, it is not possible to settle for quarterly updates. Cloud services evolve daily and impose changes on their users. Without responsiveness from product teams, production or security incidents can become major risks. A deprecated Cloud resource can also see its cost explode before being simply removed from the catalog. The best way to guard against these risks is to rely on autonomous teams. That is, multidisciplinary teams (Developers, Product Owners, Operators, etc.), responsible for both the product they develop and the impact of their choices on costs. This is the heart of the Agile approach, DevOps, DevSecOps, FinOps… and all variants that advocate collaboration rather than the segregation of responsibilities.
One team, from request to production
Traditionally, IT departments were organized by function: teams that build (project teams) and others that operate (production teams). Project teams are responsible for one or more products but depend on production teams for any changes. They do not decide how to operate their applications or even, sometimes, the underlying platform they must use. Conversely, production teams do not decide on the content of the application.
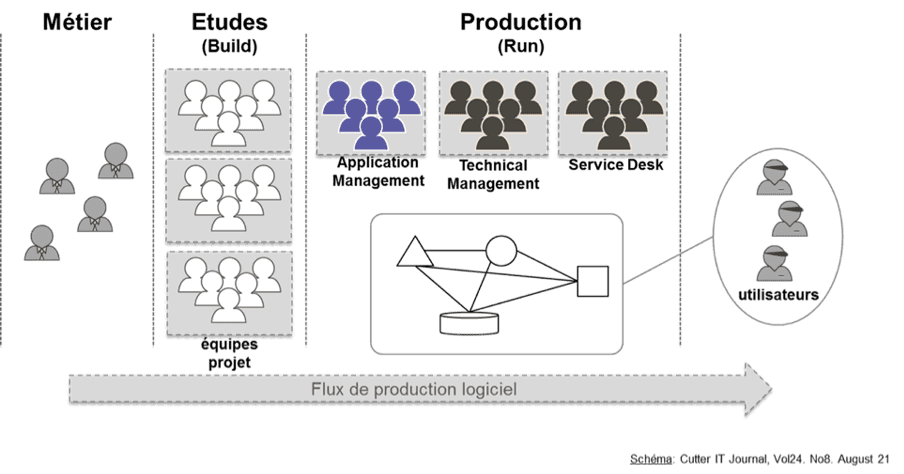
This organizational division creates problems with goal alignment and velocity. The primary objective of product teams is to evolve their products, but they are not responsible for their stability. For production teams, it's the opposite, which makes collaboration difficult. The "DevOps" approach changes this paradigm by assigning one team to one product. Each team is responsible for a product from end to end (development and run). A production deployment does not require the intervention of someone outside the team. The team is autonomous.
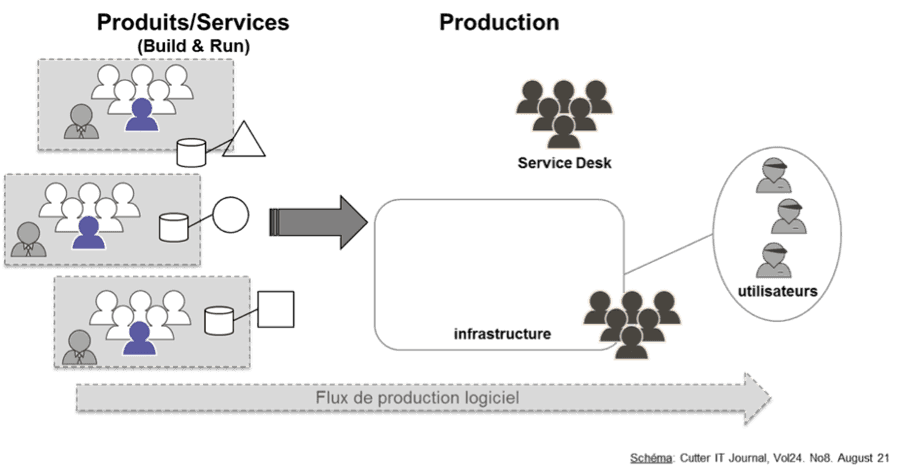
This autonomy allows product teams to monitor and modify their infrastructure in line with their needs. Making these same teams responsible also involves setting up on-call rotations and implementing SLIs, SLAs, and SLOs to ensure service continuity within a budget.
These teams are ideally composed of a maximum of about ten people. Beyond that, coordination becomes complicated, communication is diluted, and cohesion weakens, which eventually slows down decision-making and value delivery.
Production teams do not disappear, but their resources are integrated into product teams or transformed into platform teams (teamtopologies), which, like a cloud, allow product teams to pick from the service offerings made available by these platforms.
Autonomy and Velocity
An autonomous team is one capable of evolving its product with minimum friction with the rest of the organization. Its autonomy allows it to continuously adapt to feedback and customer needs to bring them maximum value. It chooses which functionality to develop as a priority and when to deploy it. Flexibility in its infrastructure choices and costs (within a defined budget) allows it to quickly test new features, validate them, and, if successful, sustain them.
Let's take a concrete example. One of our clients, with whom we implemented this operating model, wanted to use an AI model for a business need involving data classification.
When evaluating their options, the team sought a solution that optimized the following aspects:
- The ability to quickly test the solution with customers
- Ease of maintenance
- Cost
A solution was found in a few days, and within a few weeks, the first customer feedback validated the approach.
Scaling up will undoubtedly require a larger budget and therefore longer validation processes, but the business case will be easier to build (number of uses, number of interested prospects, etc.) since customers are already using the solution.
Toward a new governance model
 Source: Wikipedia
Source: Wikipedia
The DevOps approach also encourages rethinking control processes and governance roles. Having autonomous teams goes against the idea of external control gates.
In practice, going through gates to validate project resource requests often only provides an illusion of control. Refusing a request for new resources is difficult, not to mention deadlines that add significant pressure. Being able to validate a request also requires detailed knowledge of the needs. In cases where the external controller cannot have this knowledge, arbitrary validations happen very quickly. From arbitrariness comes frustration. From frustration, the desire to bypass rules or even stop innovating. It’s a lose/lose situation.
It is important to note that having autonomous teams does not mean an absence of centralized control. To ensure there are no budget overruns by teams, it is essential to have common monitoring systems and automatic remediations. The key to reacting quickly to non-standard behavior is automation. It also has the advantage of discouraging the bypassing of company rules.
An exaggerated example: one won't try to negotiate against a function that destroys any virtual machine not attached to a product team (via a tagging mechanism). People will simply follow the rule when creating the VM.
Conclusion
Autonomy and therefore responsibility of product teams are paramount in managing infrastructure costs in the Cloud.
We believe that the most effective way to do FinOps is to have multidisciplinary and autonomous teams. It is therefore about giving part of the financial and operational responsibility to the teams that manage the applications, so they can measure, understand, and optimize their costs themselves.
Concretely, this means teams must be able to visualize costs related to their assets, monitor overruns through alerts, and adjust the parameters of the resources their applications use. This includes, for example, VM sizes, storage topology, or the service level of SaaS offerings.
We believe that governance roles have everything to gain by evolving from a logic of validation to a logic of support. Their mission is no longer to slow down or block, but to advise, guide, and evangelize best practices (10 Ways to work WITH Developers to take action with FinOps). The goal is to allow greater velocity for teams while maintaining controlled cost management.
While we recognize the need to monitor the work of teams, we believe above all that they must be autonomous and responsible in their decisions.